

In machine learning, one of the primary objectives is to learn from past data and be highly accurate at guessing what future data is going to reveal. This focus on guessing what will happen shows how important it is for a machine learning model to be able to work well with data it hasn't seen before. Validation is an important tool that lets us see how well a model is going to do on new or previously unseen data, data that the model hasn't been trained on or hasn't seen yet.
This article goes into cross-validation, which is another important idea in machine learning and data science. We’ll cover what it is, we’ll examine different types and gain insights into its significance.
Why is Cross-Validation Important
Let's first see why cross-validation is important before we get into our main topic. Let's say you want to teach a computer vision model to tell the difference between dog breeds based on pictures. You show the model a variety of pictures of dogs of different breeds, like Labradors, Poodles, and Bulldogs. At first, it looks like the model is learning well because it can correctly name the different breeds in the training set.
That being said, when you test the same model in the real world, like at a park, it starts to get breeds wrong. All of a sudden, it calls every dog a Labrador, no matter what breed it is. Overfitting is what happened here. The model remembered the details of the training data so well that it has trouble applying what it has learned to new situations.
Overfitting basically happens when a machine learning model focuses too much on the details of the training data and memorizes them too well, missing out on general patterns that could be used with new examples it hasn't seen before. This is exactly where cross-validation comes in handy.
What is Cross-Validation
Cross validation is a powerful tool in machine learning that evaluates the performance of a model. It's a resampling technique that splits the data into several subsets and then uses each subset to train and test the model.
Cross-validation checks how well a model works on data it hasn't seen before. This is done to avoid overfitting problems. It mimics real-life situations where the model comes across examples it hasn't seen before.
Let's look at how cross-validation works. It starts with raw data that is then split into two sets:
- the training set is where the model learns
- the testing set checks how well the model works with data it hasn't seen before
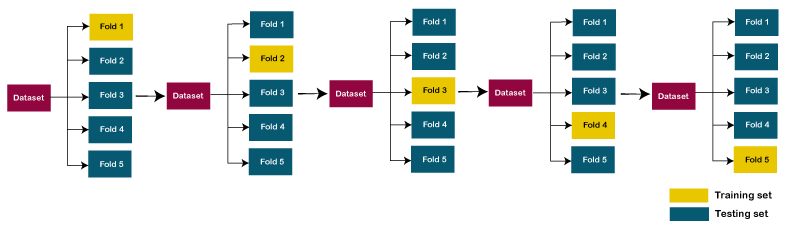
In the next step, the test data set is changed over and over again while the remaining data sets are used to train the model. This process will keep going until all of the subsets have been used as test data. In the last step, the average performance across all of these testing sets is found. This gives a more accurate picture of how well the model works with new data that wasn't in the training set.
Cross-validation gives a full picture of the model's generalization by simulating different training and testing situations. This makes it possible to find hyperparameters that have been over-adjusted and makes it easier to compare models. Cross-validation basically acts as a link between how well a model does on well-known training data and how well it can handle new situations in the real world. It helps avoid the problems that come with overfitting and underfitting, making models that are strong and really understand how they learn.
Different Cross Validation Types
Now, let's delve into the various types of cross-validation and examine each one in detail. The types we'll cover include Leave-One-Out Cross-Validation, Hold-Out Cross-Validation, K-Fold Cross-Validation, and Stratified K-Fold Cross-Validation. Let's take them step by step, starting with Leave-One-Out Cross-Validation.
Leave One Out Validation
When discussing Leave-One-Out Cross-Validation, consider a training dataset with 100 records. In this approach, one record is selected for the validation set, while the remaining 99 form the training set. In subsequent iterations, you progressively omit each record used for validation initially. For instance, in the second iteration, the second record becomes the validation set, and this process continues until the 100th record is used as the validation set.
This method, though somewhat outdated, provides a clear understanding. It involves taking each record, one at a time, as the validation set while utilizing the rest for training. However, it is not widely used due to its inherent time-consuming nature. Iterating through each record individually can be impractical, and ensuring each record serves as part of the validation set can lead to overfitting.
Hold Out Cross-Validation
In Hold-Out Cross-Validation, considering you have 100 records, 75 percent of these records are designated as the training set, while the remaining 25 percent are allocated to the validation set. This division is based on a percentage, with 75 percent for training and 25 percent for validation, defining the Hold-Out Cross-Validation approach.
However, it's crucial to note that this method is not immune to challenges such as overfitting and underfitting. Outliers in the dataset can significantly impact the model's training process. For instance, if there's an exceptionally large record in the training dataset, it may distort the model's training, leading to potential overfitting or underfitting scenarios. Therefore, Hold-Out Cross-Validation, while straightforward, demands attention to potential outliers that could influence the model's performance.
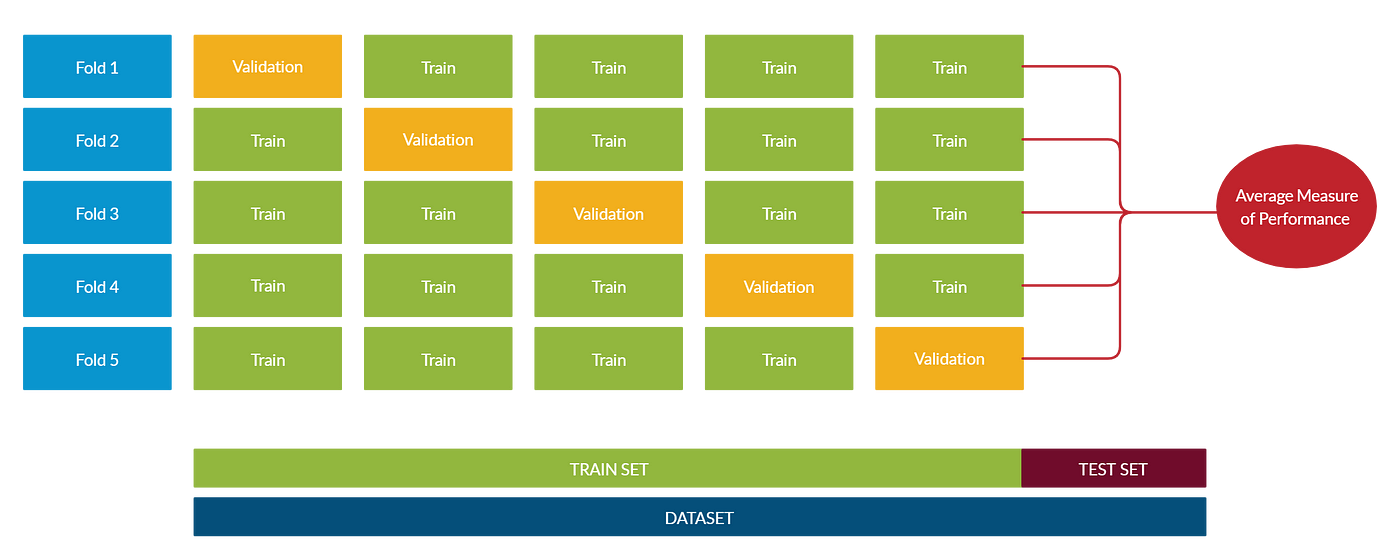
K-Fold Cross Validation
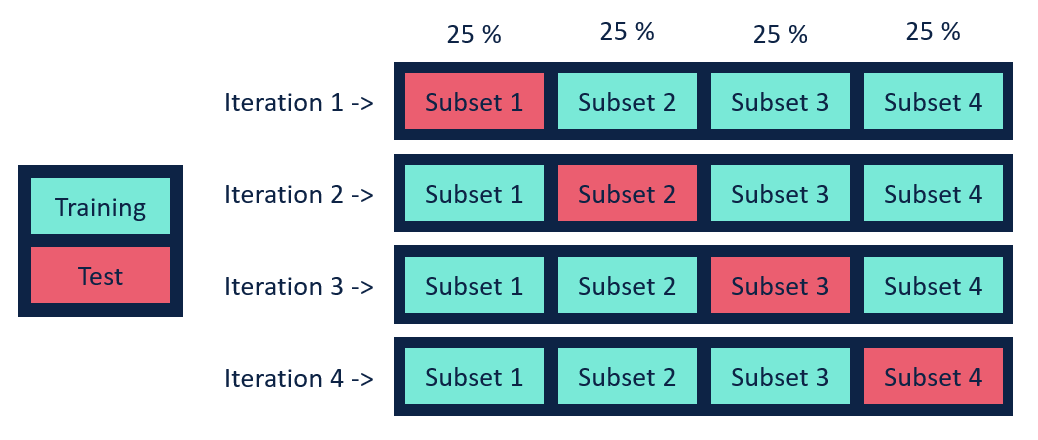
The next method, and one of the commonly used techniques, is K-Fold Cross-Validation. For instance, if you have 100 records and opt for five iterations, each iteration involves using 20 records for the validation dataset, while the remaining 80 records form the training dataset.
With the iteration value set to 5, there will be five iterations. In each iteration, meticulous care is taken to ensure that every 20-block of data is considered. This means that the same 20 records selected in one iteration are not reused in subsequent iterations. Instead, each iteration introduces a fresh set of 20 records. This systematic process is crucial for calculating errors and accuracy, and subsequently, the accuracy is averaged based on these errors.
Stratified K-Fold Cross Validation
This approach is tailored to handle datasets with multiple classes. If your test dataset comprises two classes, let's say Class A and Class B, the stratified approach allows you to define the distribution within each iteration. For instance, you can specify using 70 percent of Class A and 30 percent of Class B, or opt for a distribution like 60 percent Class A and 40 percent Class B, or even a balanced 50-50 split between both classes.
This method, ensures that each iteration maintains a proportionate representation of the different classes, mitigating potential issues arising from imbalances in the dataset. Even when dealing with outliers, where the output value is substantially larger than the input values, this approach remains effective. Stratified K-Fold Cross-Validation is commonly employed, especially in cases of imbalanced datasets.
Benefits of Cross Validation
As we mentioned earlier, the first benefit is that it helps avoid overfitting. Cross-validation helps stop overfitting by giving a more accurate picture of how the model works on data it hasn't seen yet.
The second benefit has to do with choosing a model. The goal of cross-validation is to find the model that consistently performs the best on average and then choose that one.
Cross-validation is a key part of hyperparameter tuning, which brings us to the third benefit. Hyperparameters of a model, like the regularization parameter, can be made better with its help. For this optimization, you have to pick the values that give you the best performance on the validation set.
Finally, the fourth benefit is that it makes data more efficient. Cross-validation lets you use all of your data for both the training set and the validation set. This makes it a better way to use data than traditional validation methods. This makes sure that the model is fully trained and tested, which makes the dataset more useful.
Challenges of Cross Validation
Finally, let's delve into the challenges and considerations associated with cross-validation. Firstly, there's the issue of increased computational cost, demanding significant processing power, especially when dealing with large datasets. This arises from the necessity for multiple training iterations, adding to the overall computational load.
Another challenge lies in the selection of the parameter K, representing the number of folds. This choice plays a critical role in the bias-variance tradeoff. Opting for values that are too low or too high can introduce problems. It's essential to determine the optimal number of folds, striking a balance to avoid biases. Achieving this equilibrium ensures that the results are not influenced adversely by an excessively low or high number of folds.
Furthermore, it's crucial to acknowledge that the outcomes can vary based on how the data is divided. This variability emphasizes the need for thoughtful consideration when implementing cross-validation to ensure reliable and consistent results.
Conclusion
Cross-Validation can help with common problems in machine learning, like overfitting, model selection, hyperparameter tuning, and making the best use of data. Even though there are clear benefits, practitioners have to deal with problems like higher computing costs and picking the right fold parameter (K). To avoid biases and improve the model's generalizability, it's important to find the right balance. When used correctly, Cross Validation is an important tool that bridges the gap between model training on familiar data and its ability to navigate real-world scenarios with unseen examples. Its impact on improving model performance and reliability solidifies its place as a cornerstone in the arsenal of machine learning practitioners.
Transform Your Business and Achieve Success with Solwey Consulting
At Solwey Consulting, we specialize in custom software development services, offering top-notch solutions to help businesses like yours achieve their growth objectives. With a deep understanding of technology, our team of experts excels in identifying and using the most effective tools for your needs, making us one of the top custom software development companies in Austin, TX.
Whether you need ecommerce development services or custom software consulting, our custom-tailored software solutions are designed to address your unique requirements. We are dedicated to providing you with the guidance and support you need to succeed in today's competitive marketplace.
If you have any questions about our services or are interested in learning more about how we can assist your business, we invite you to reach out to us. At Solwey Consulting, we are committed to helping you thrive in the digital landscape.



Never miss anything!
Get weekly updates on the latest automation trends and design news.
Let's get started
If you have a vision for growing your business, we're here to help bring it to life. From concept to launch, our award-winning team is dedicated to helping you reach your goals. Let's talk.