
Hugging Face: The Open-Source Platform for AI and Machine Learning

Hugging Face has recently become a significant player in the AI field, serving as a vital tool that allows developers to easily utilize open-source AI models. It is an open-source data science and machine learning platform that has cultivated a strong AI community. Understanding how Hugging Face works is necessary for keeping up with the latest developments in AI and machine learning. If you are an AI developer working with models to train datasets or if you have a dataset suitable for training a new model, it's important to get acquainted with this platform.
Discover why Hugging Face is the go-to platform for AI enthusiasts and developers worldwide. Explore its extensive repository of models, learn how to fine-tune your projects with comprehensive datasets, and experience the seamless deployment of your applications in Spaces.
Hugging Face: The GitHub for AI and Machine Learning
Hugging Face can best be described as a repository for open-source AI models, similar to GitHub but focused on AI and machine learning.
Generally, a machine learning or AI developer engages in three main activities:
- Building a model or reusing an existing one,
- Training these models with datasets,
- Deploying the trained models.
Hugging Face provides a comprehensive platform to facilitate these processes. It has three major components that we’ll see in greater detail.
Hugging Face Models
Hugging Face offers an open-source way to share and access models within the community. By using inference APIs, developers can test and evaluate these models' performance. These models could range from language models (like large language models or LLMs) to computer vision models and other domain-specific models.
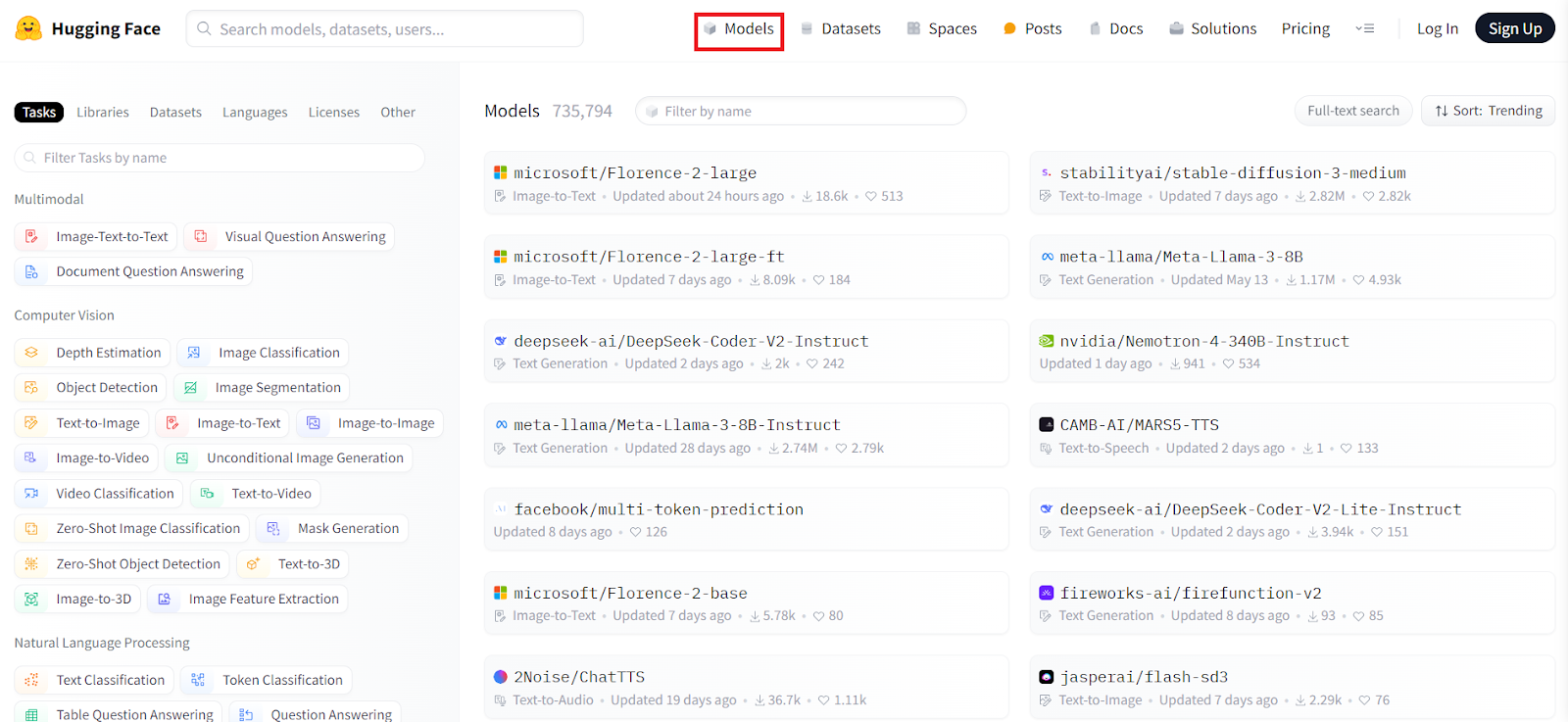
If we click on the Models option in the navigation bar, we can see that Hugging Face offers a vast collection of open-source AI models—over 730,000, to be precise. These models are well-organized into categories such as computer vision, natural language processing (NLP), and audio. There are also multi-modal models, which combine different types of data.
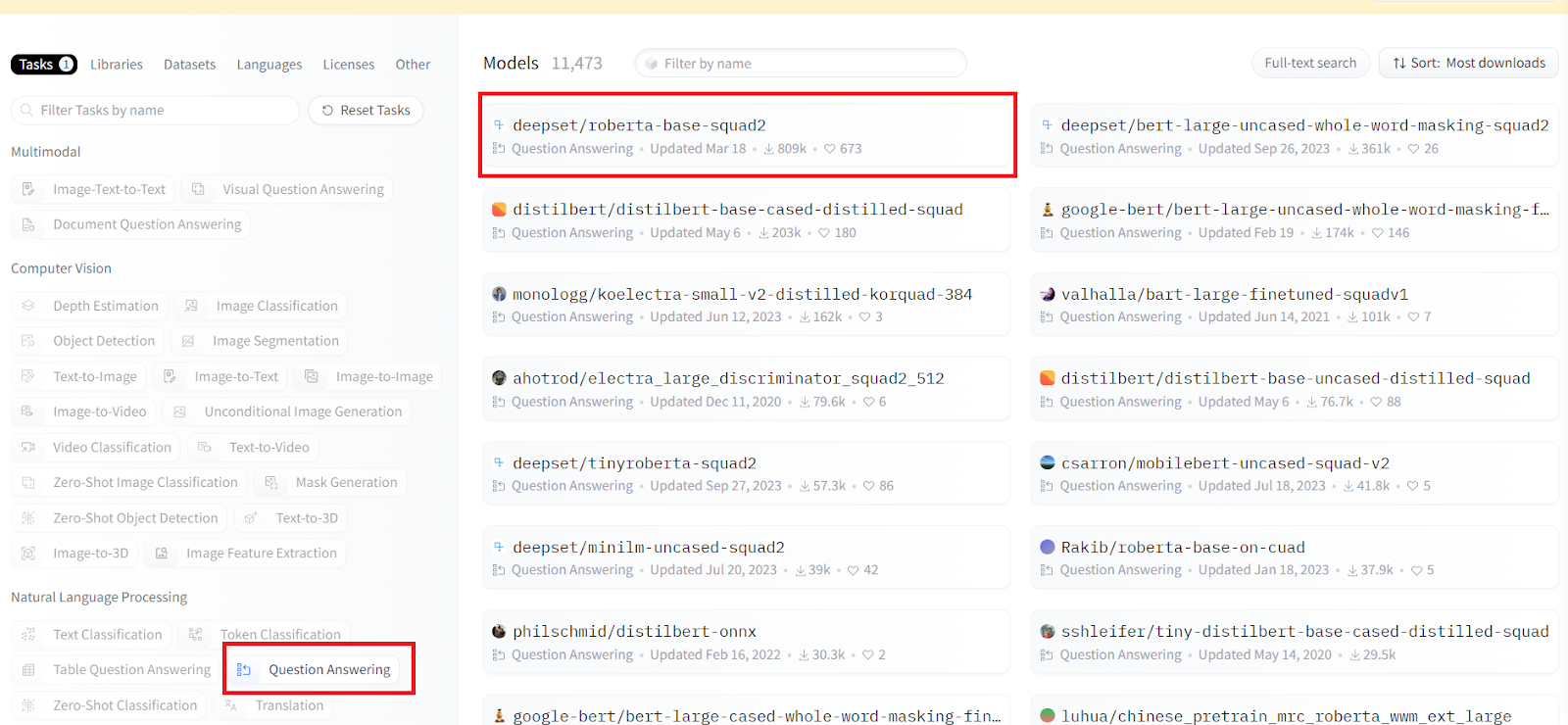
For example, if we explore the question answering subcategory under NLP, we find a version of the BERT model fine-tuned for answering questions based on given contexts. One of the great features of Hugging Face is that it allows us to test the AI model directly on the interface. For instance, given the context "Hugging Face is a company that develops tools for natural language processing," and the question "What does Hugging Face develop?", the AI model predicts "tools for natural language processing."
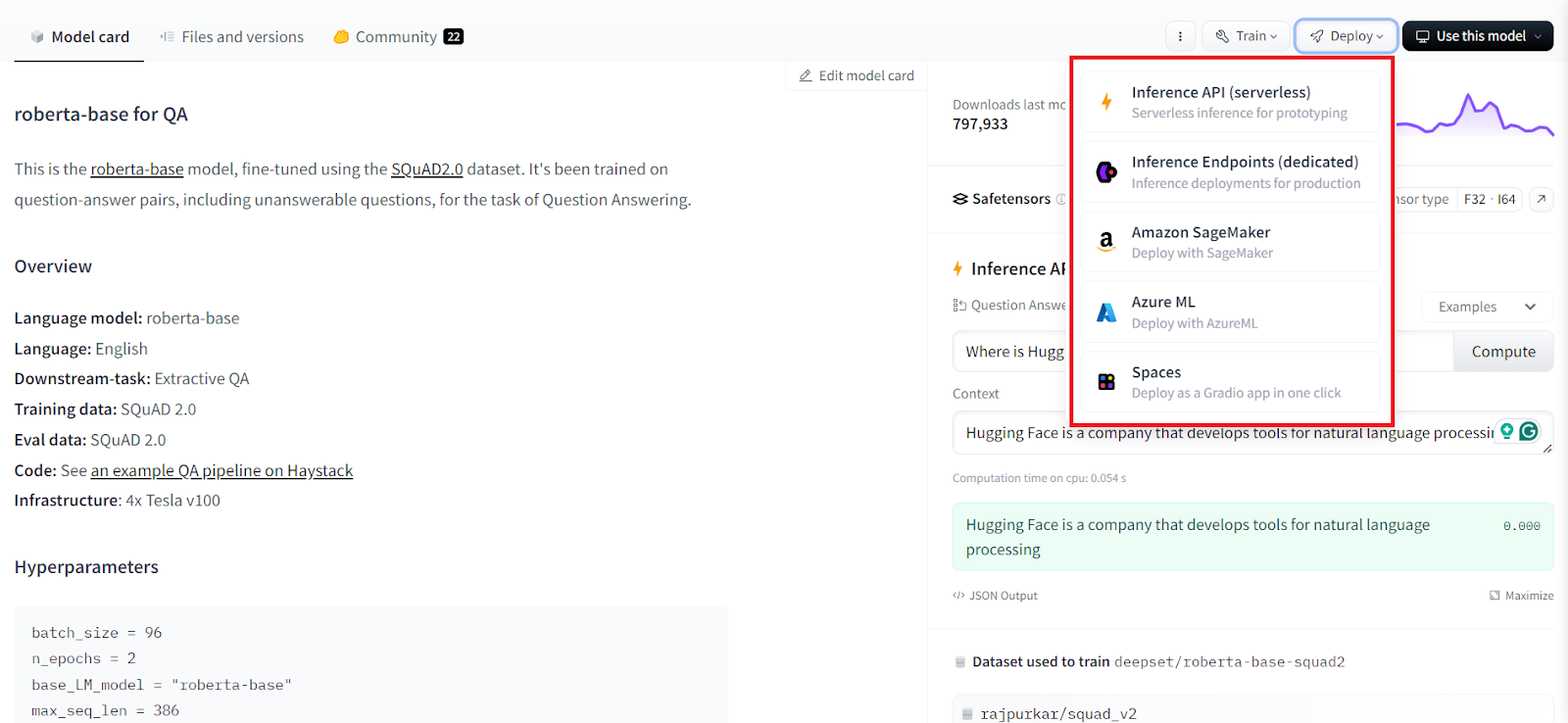
Another advantage of Hugging Face is the ease of deploying these models. With just one click, you can deploy the AI model to the Inference API, Amazon SageMaker, or Azure ML. Additionally, the "Use in Transformers" button provides the Python code needed to integrate the AI model into your Python application. More about Transformers in a little bit.
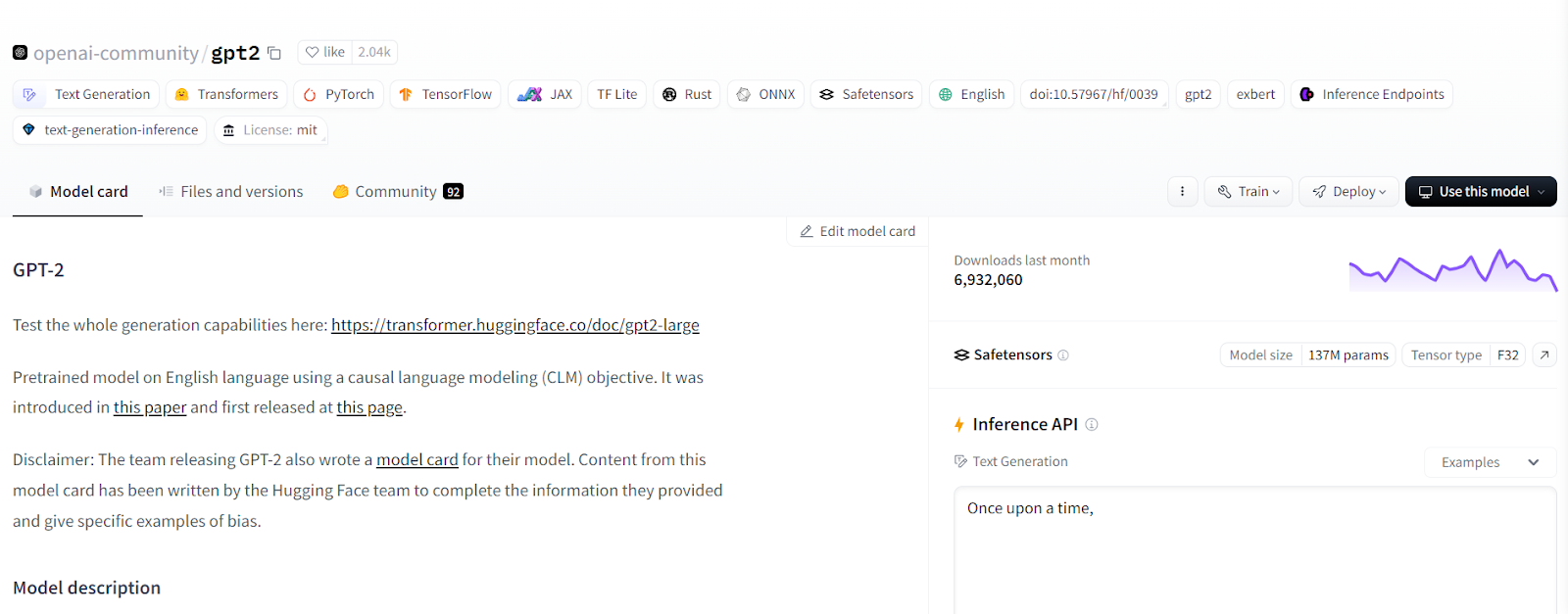
Hugging Face's utility extends beyond just providing access to these models. For example, searching for "GPT-2" in the search bar reveals the precursor to OpenAI's GPT-3. Unlike GPT-3, GPT-2 is open-source and available on Hugging Face, showcasing its popularity with numerous downloads.
Moreover, Hugging Face offers uncensored data models, which are trained without ethical restrictions or biases. Users can explore these models by searching for "uncensored" in the search bar. Hugging Face also allows anyone to upload their own AI models, encouraging a diverse and expansive community of developers.
With such a wide array of utilities and models, Hugging Face truly serves as a comprehensive platform for AI and machine learning enthusiasts.
Hugging Face Datasets: A Resource for Model Fine-Tuning
Hugging Face doesn't just offer AI models; they also provide a wide array of datasets. Developers can split these datasets and use them for training. The platform shows how the data is structured, including the different columns and other relevant details. This feature is also open-sourced, making it accessible to everyone.
By clicking on the Datasets option in the navigation bar, you can access a vast collection of well-organized datasets. This resource is incredibly useful if you're looking to fine-tune your AI models on specific data.
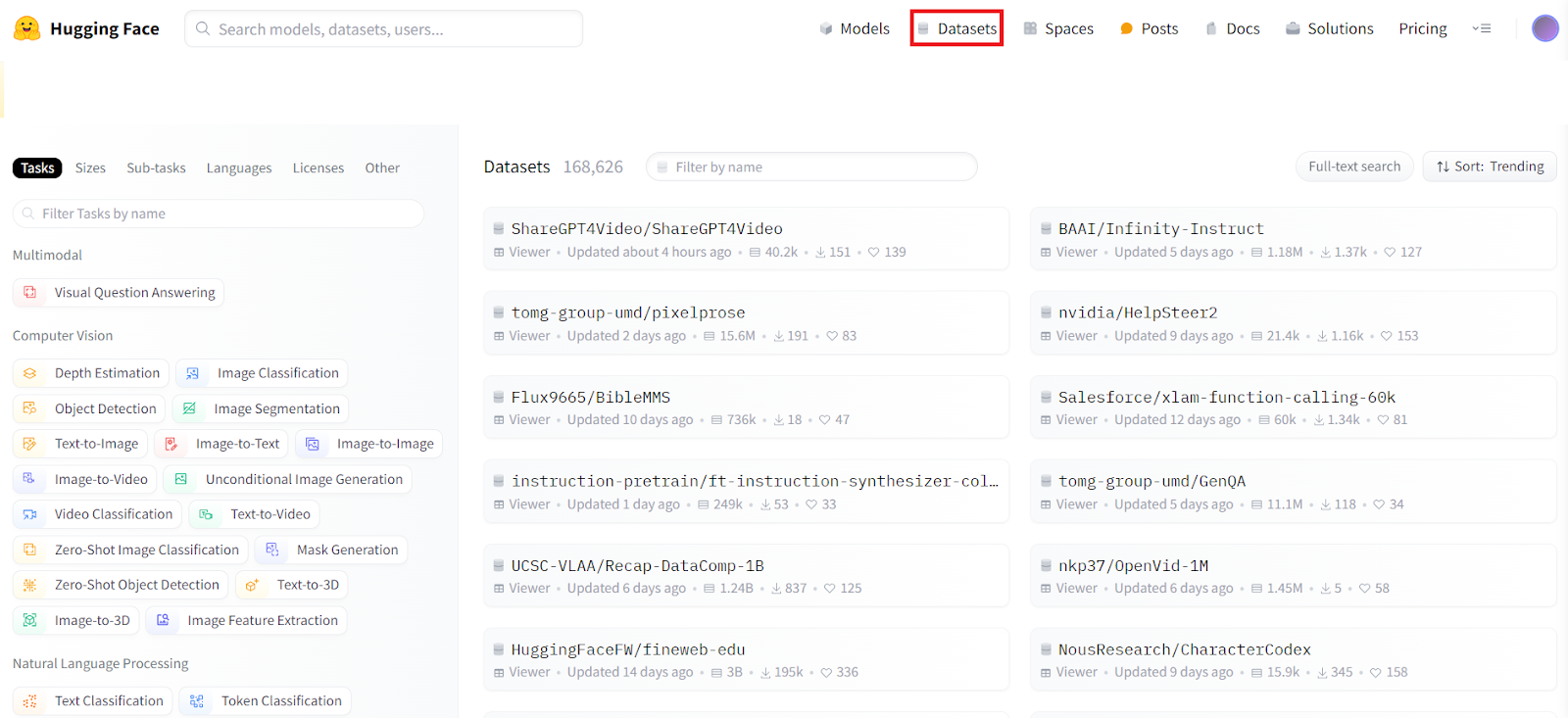
For example, if we explore the computer vision section and select image segmentation, we can choose a dataset like the COCO dataset. This dataset contains over 330,000 images. Clicking on an image within this dataset, you might see an image of a busy street scene with annotated regions. By expanding the segmentation column, you will see these regions represented by pixel masks, which help label the data.
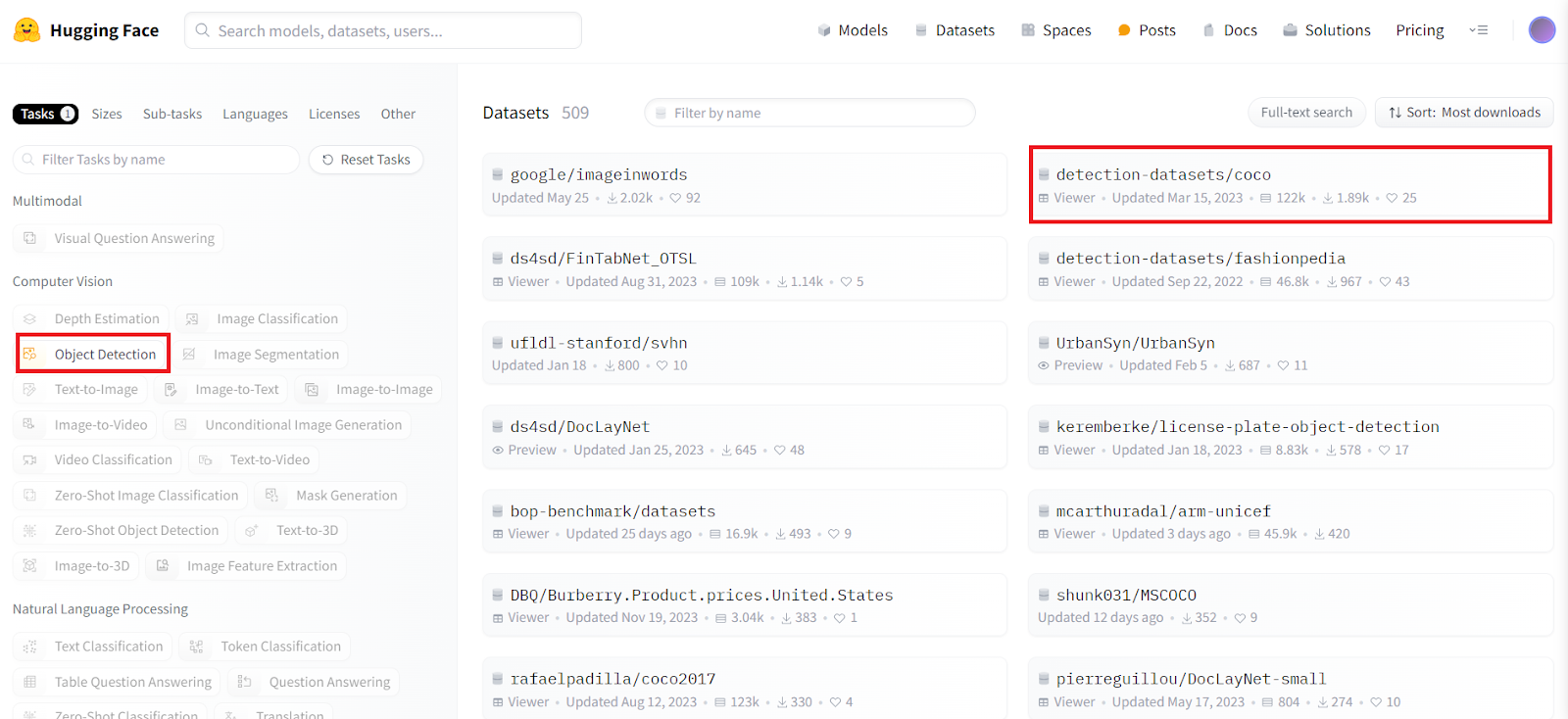
For the COCO dataset, each object in the street scene is labeled with pixel masks. For example, the dataset labels the cars, pedestrians, and traffic signs, providing the exact pixel coordinates for each object. This labeling system applies to all 330,000 images, allowing the AI to be trained to accurately segment and identify similar objects in new, unseen data.
These datasets, complete with detailed labeling, are essential for training AI models to recognize and classify various objects accurately. Hugging Face's extensive and organized datasets make it easier for developers to fine-tune their models effectively.
Hosting AI Models and Apps with Hugging Face Spaces
Finally, Hugging Face offers Spaces, a hosting service for the models trained with your datasets. You can build a custom model, train it with a new dataset, upload it, and deploy it in Spaces. This allows your application to run and be used by others as an example.
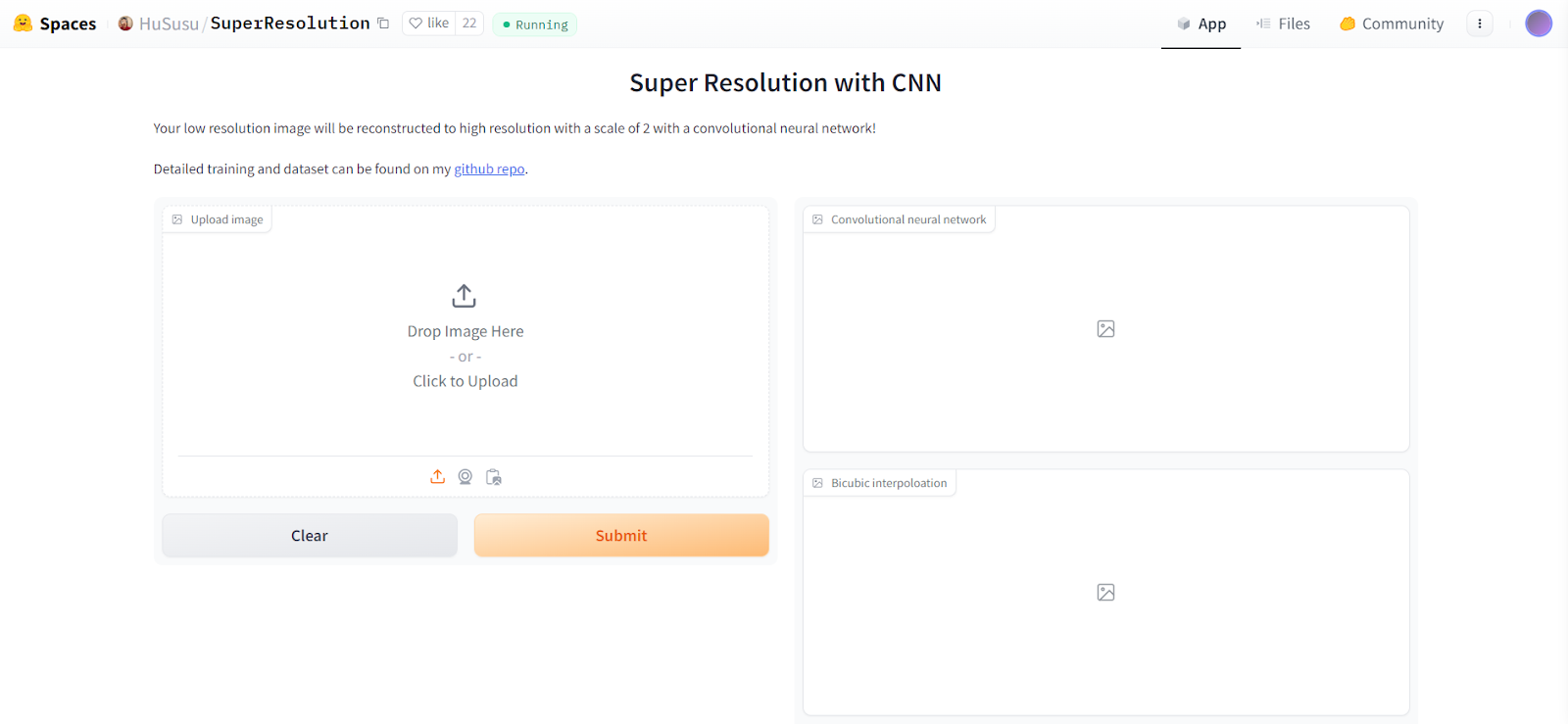
There are numerous examples available, and you can use the search bar to find specific models. For instance, searching for "super-resolution" brings up the Super Resolution with CNN model. By clicking on it, you can view the app in action. The app provides several example images and you also have the option to upload your own low-resolution images to see how they are enhanced.
Hugging Face Transformers Library
While these three components of Hugging Face's ecosystem have made developing machine learning models more accessible than ever before, there's still another key element worth mentioning: the Transformers library. Transformers is a Python library developed by Hugging Face that simplifies downloading and training machine learning models. Originally designed for natural language processing, its current functionality spans various domains, including computer vision, audio processing, and multimodal problems.
To illustrate how easy it is to get started with the Transformers library, let's look at a concrete example. Suppose we want to perform text summarization. Typically, this task involves multiple steps: finding a suitable model, preprocessing the text, passing it into the model, and processing the model's output to get a summary. While this process might seem complex, the Transformers library simplifies it into a single line of code using the pipeline function.
Here's an example:
from transformers import pipeline
summarizer = pipeline('summarization')
result = summarizer('Hugging Face has released various tools and libraries that make developing and deploying machine learning models more accessible. Their Transformers library is particularly powerful, offering functionality across different domains, including natural language processing, computer vision, and audio processing. With a user-friendly interface and a vast collection of pre-trained models, the Transformers library simplifies complex tasks such as text summarization, sentiment analysis, and more.')
print(result)
The output of this code is a concise summary of the input text. This makes text summarization incredibly straightforward. However, summarization is just one of many tasks you can perform with the pipeline function. Other tasks include sentiment analysis, translation, question answering, feature extraction, text generation, and more. For a full list, you can refer to Hugging Face's documentation.
In our example, we didn't specify a model; we simply asked for text summarization. The library used a default model, which is typically facebook/bart-large-cnn for summarization tasks. You can also specify a different model if you prefer:
summarizer = pipeline('summarization', model='facebook/bart-large-cnn')
What makes Transformers powerful is the flexibility to use any of the thousands of models available on Hugging Face. This versatility, combined with its ease of use, makes the Transformers library a crucial component of the Hugging Face ecosystem.
Why Choose Hugging Face Over Proprietary AI Models?
A common question is why you should use these open-source models instead of proprietary ones like OpenAI's GPT. There are several important considerations to keep in mind.
One concern with proprietary models like GPT is data privacy. When you train GPT using your proprietary data, that data must be sent to OpenAI's servers, and OpenAI has the right to train its own models based on your data. With open-source AI models, you can train them locally, ensuring that your proprietary data does not leave your local environment. This is particularly important if you are subject to national privacy laws such as GDPR in the European Union, which may prohibit sending customer data to third-party servers.
Another issue is that GPT itself is proprietary and not open source. The model you train will reside on OpenAI's servers, and you will not have direct access to it. You will only be able to send requests to get responses. This means that the valuable intellectual property developed by training your AI model will be owned by OpenAI, not you. In contrast, with open-source AI models, you can train them locally and retain control over your intellectual property.
Cost and performance are also key factors. Using OpenAI's GPT requires paying for every API call to their servers. While OpenAI handles all the ML Ops for you, avoiding the need to deploy your own AI model, this convenience comes at a cost. Deploying your own AI model can result in much lower ongoing costs. Additionally, while GPT excels at many tasks, for niche problems, there may be specialized open-source AI models that offer better performance.
In summary, using open-source AI models from Hugging Face allows you to maintain data privacy, control your intellectual property, reduce costs, and potentially achieve better performance for specialized tasks.
Transform Your Business and Achieve Success with Solwey Consulting
Hugging Face is an end-to-end platform for building, training, and deploying data models, and it is completely open-source. If you come from a software engineering background, think of Hugging Face as the GitHub for AI and machine learning. They aim to make the learning curve of AI and machine learning less steep by introducing solutions that allow non-technical people, or technical people with little or no AI experience, to onboard more easily.
Solwey Consulting is your premier destination for custom software solutions right here in Austin, Texas. We're not just another software development agency; we're your partners in progress, dedicated to crafting tailor-made solutions that propel your business towards its goals.
At Solwey, we don't just build software; we engineer digital experiences. Our seasoned team of experts blends innovation with a deep understanding of technology to create solutions that are as unique as your business. Whether you're looking for cutting-edge ecommerce development or strategic custom software consulting, we've got you covered.
We take the time to understand your needs, ensuring that our solutions not only meet but exceed your expectations. With Solwey Consulting by your side, you'll have the guidance and support you need to thrive in the competitive marketplace.
If you're looking for an expert to help you integrate AI into your thriving business or funded startup get in touch with us today to learn more about how Solwey Consulting can help you unlock your full potential in the digital realm. Let's begin this journey together, towards success.



Never miss anything!
Get weekly updates on the latest automation trends and design news.
Let's get started
If you have a vision for growing your business, we're here to help bring it to life. From concept to launch, our award-winning team is dedicated to helping you reach your goals. Let's talk.